
大模型如何进行微调?
前言
本次我将使用Qwen2.5-3B模型配合LlamaFactory+llama.cpp+ollama等相关技术实现大模型微调以及部署到本地
环境准备
全部环境需要算力云,本地电脑环境需要python,cmake,docker desktop,ollama,llama.cpp等。我们先安装部分环境,之后在微调部署过程中再安装剩余环境。
算力云
训练大模型用到的硬件配置很高,所以我推荐使用云服务器,例如AutoDL,阿里云。
这里我白嫖阿里云免费的算力,阿里云-人工智能平台 PAI,
 有个免费试用,选择交互式建模DSW,开通,选择配置,我选择的配置如下:
有个免费试用,选择交互式建模DSW,开通,选择配置,我选择的配置如下:
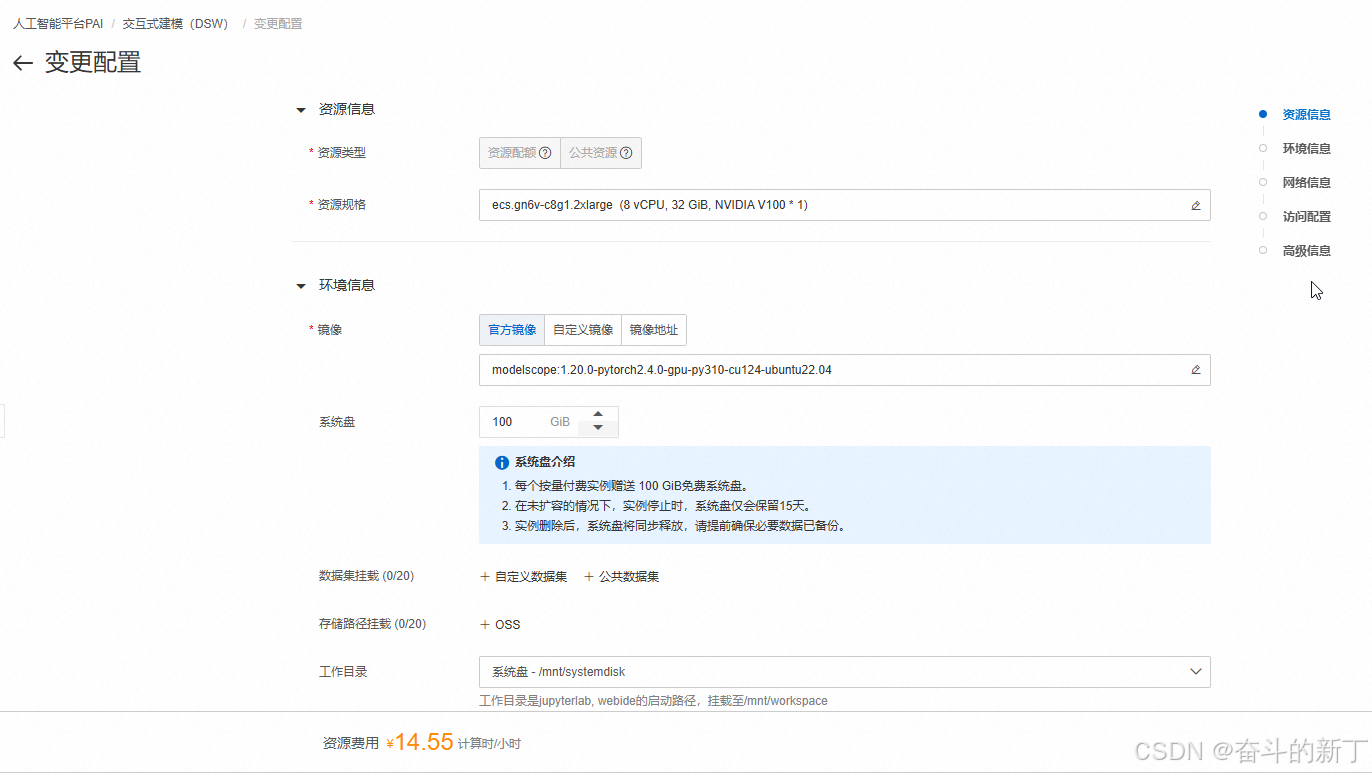
注意,下面有个14.55计算时/小时,试用是三个月,每个月250计算时,也就是能用16个小时左右,注意不要用超时,费用还是很贵的o(╥﹏╥)o。
python
我安装的是python3.9,安装教程百度即可。
ollama
下载地址
安装即可
微调
下载模型
大模型有很多,国外我们登录Hugging Face,可以训练llama3。
国内用户登录魔搭社区 ,这次选用的是Qwen/Qwen2.5-3B-Instruct训练。
这里我们使用SDK下载模型,复制命令
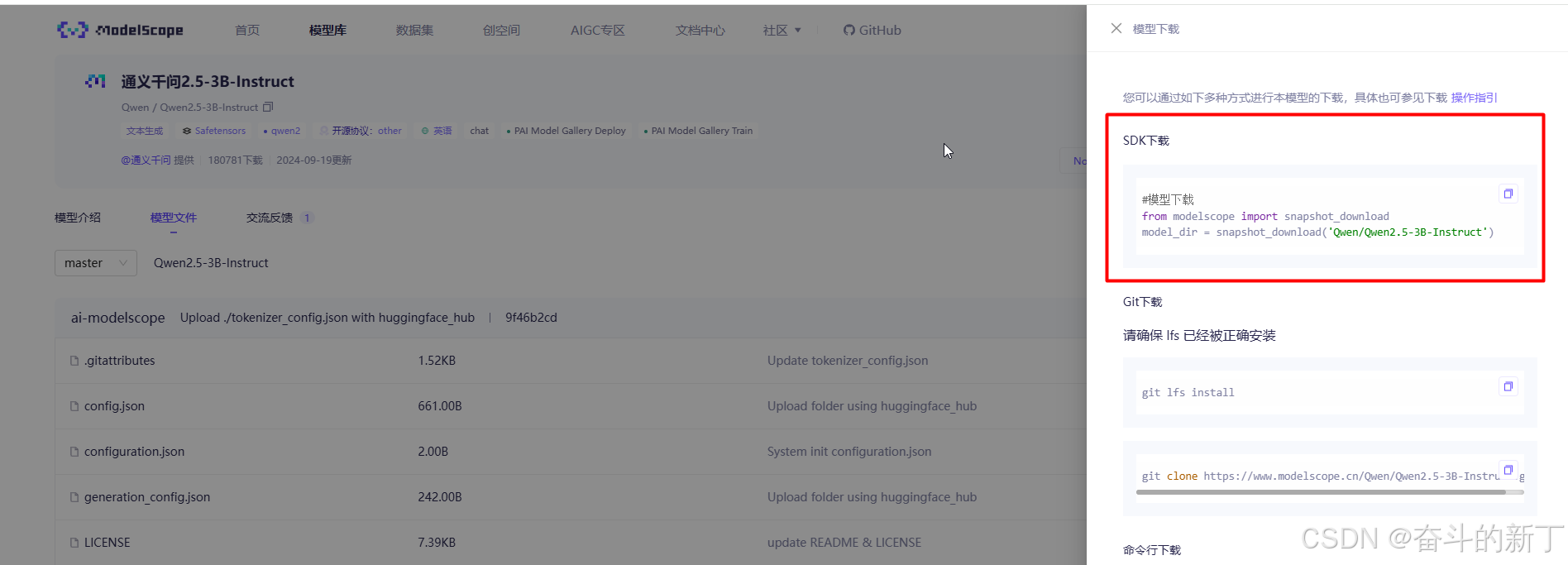
从阿里云中打开我们申请的实例
新建一个py文件,执行下载。
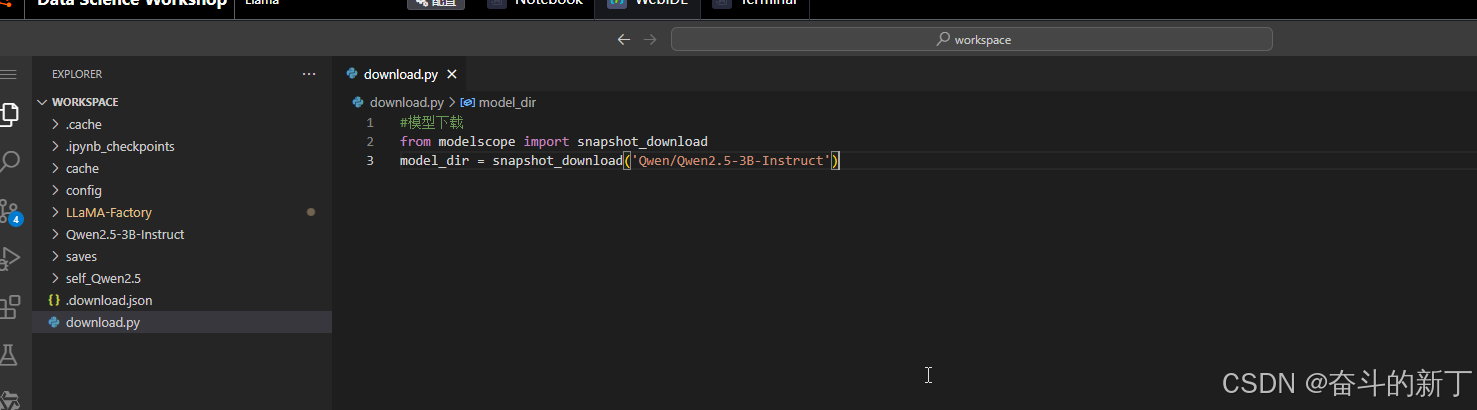
下载成功后模型在/mnt/workspace/.cache/modelscope/hub/Qwen/Qwen2.5-3B-Instruct这个位置
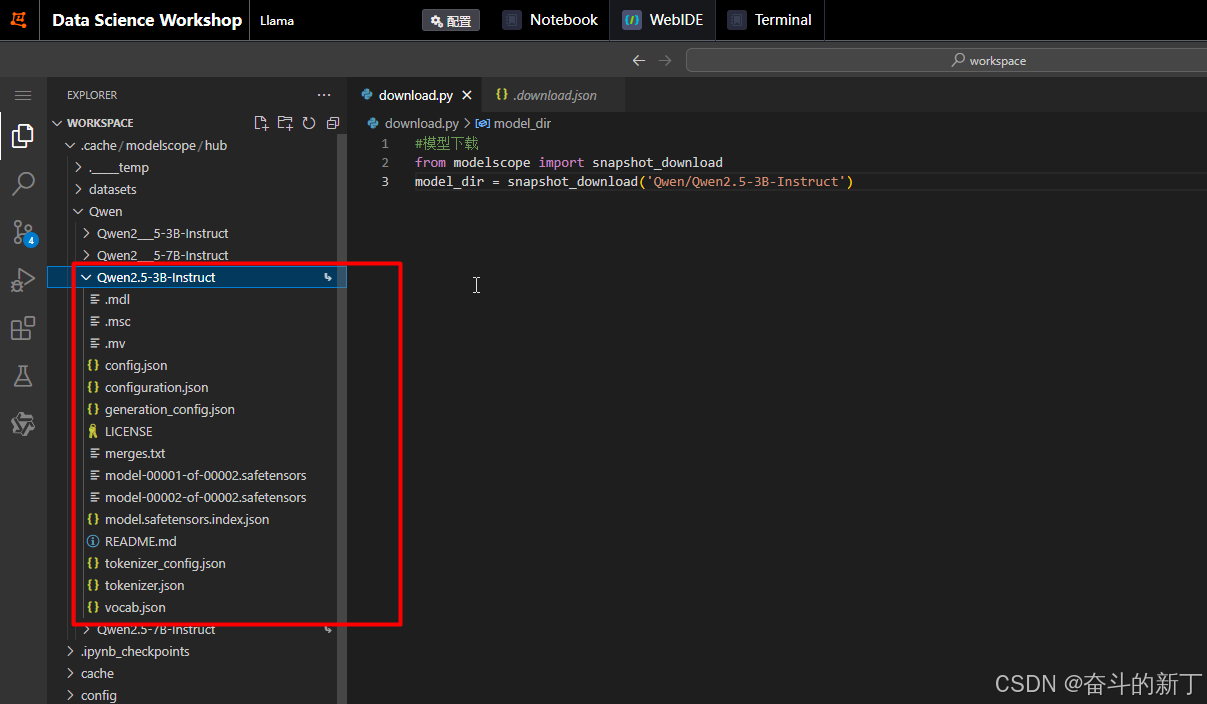
安装Llamafactory
继续在阿里云中安装llamafactory
从github下载llamafactory
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git1
下载完成后,安装相关依赖
cd LLaMA-Factorypip install -e ".[torch,metrics]"12
输入可视化页面启动命令
llamafactory-cli webui1
 可以看到服务已经在7860端口上运行,点击链接进入web页面
可以看到服务已经在7860端口上运行,点击链接进入web页面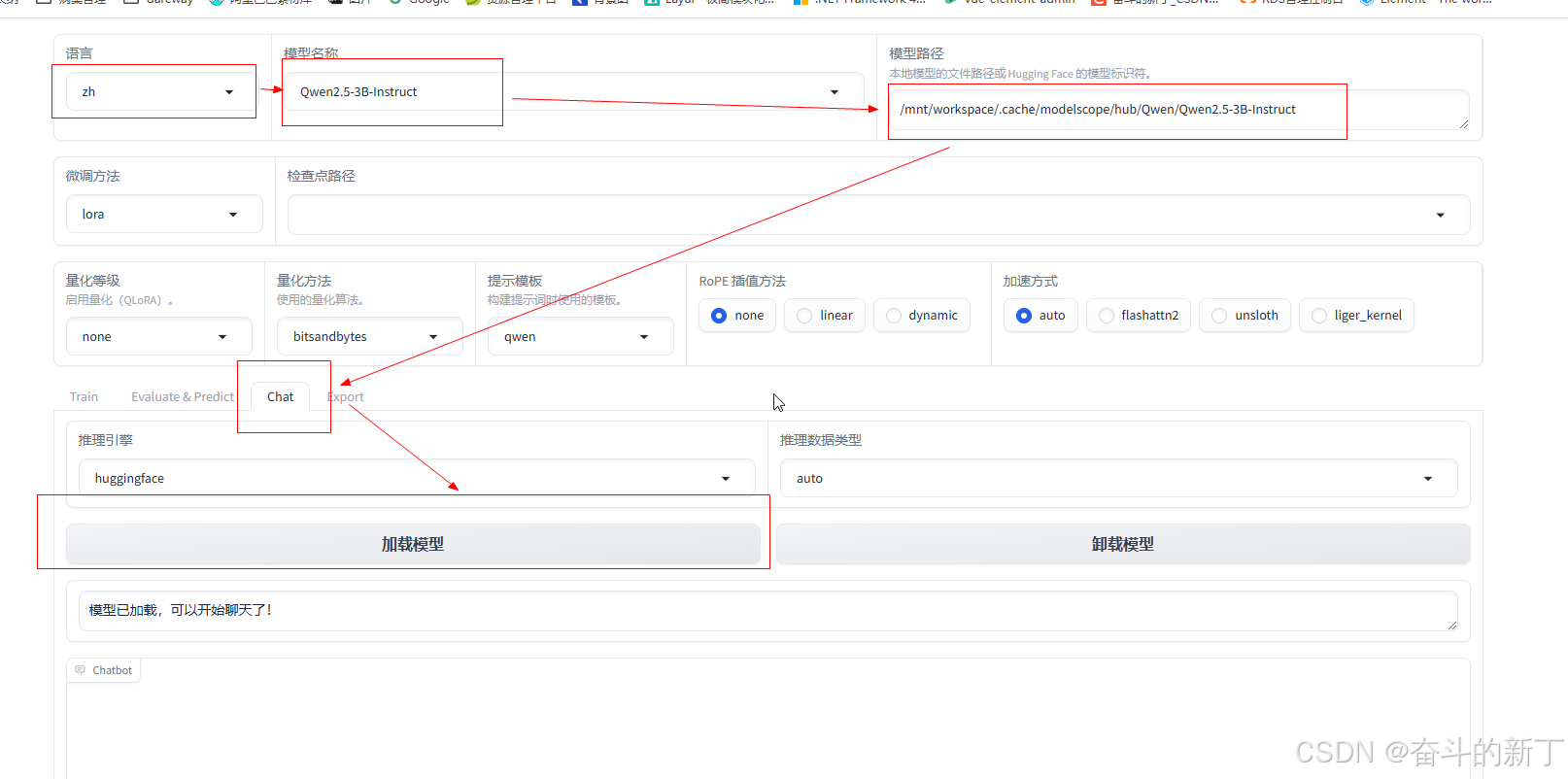 依次选择语言,模型名称,将上面下载的模型路径填上,点击chat,加载模型。
依次选择语言,模型名称,将上面下载的模型路径填上,点击chat,加载模型。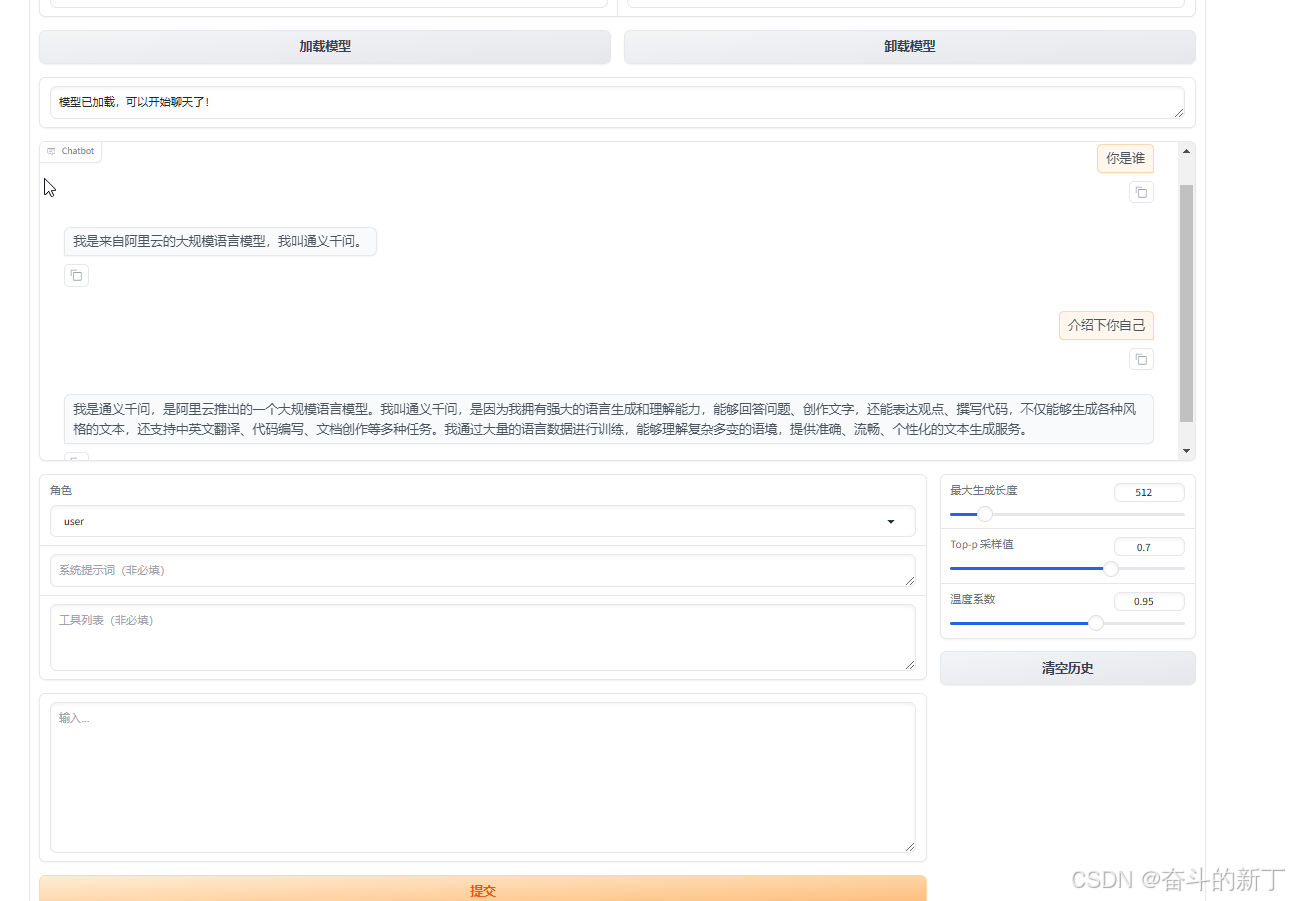 问它关于自己的问题,可以看到它的回复。
问它关于自己的问题,可以看到它的回复。 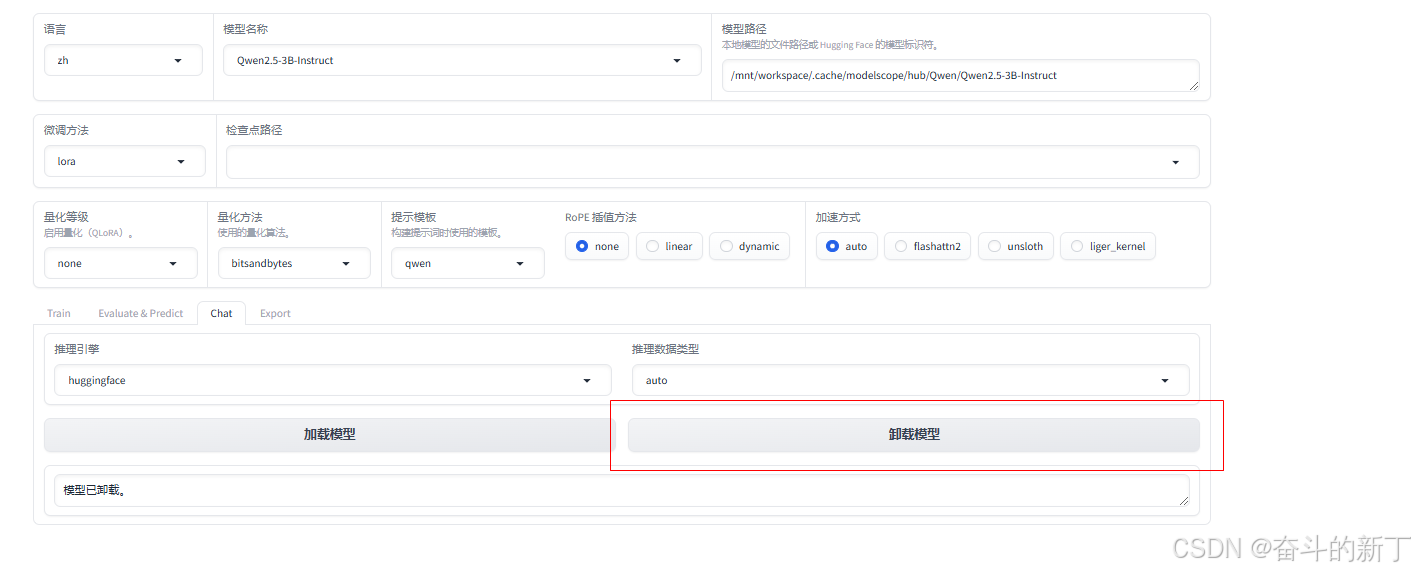 使用完成后记得卸载模型,避免占用资源。<br/> 到这里一个通用的大模型就搭建完成了,接下来我们需要进行微调,改变它的个人信息。
使用完成后记得卸载模型,避免占用资源。<br/> 到这里一个通用的大模型就搭建完成了,接下来我们需要进行微调,改变它的个人信息。
准备数据集
 首先我们准备好这种格式的json文件,这个文件起名叫self_cognition.json。将其放在安装的LLaMA-Factory下的data下,并且在dataset_info.json中配置上该文件
首先我们准备好这种格式的json文件,这个文件起名叫self_cognition.json。将其放在安装的LLaMA-Factory下的data下,并且在dataset_info.json中配置上该文件
训练
数据集准备完成后,然后llamafactory的web页面选择刚才添加的数据集,修改训练轮数,这里我选择训练20次,点击开始训练即可。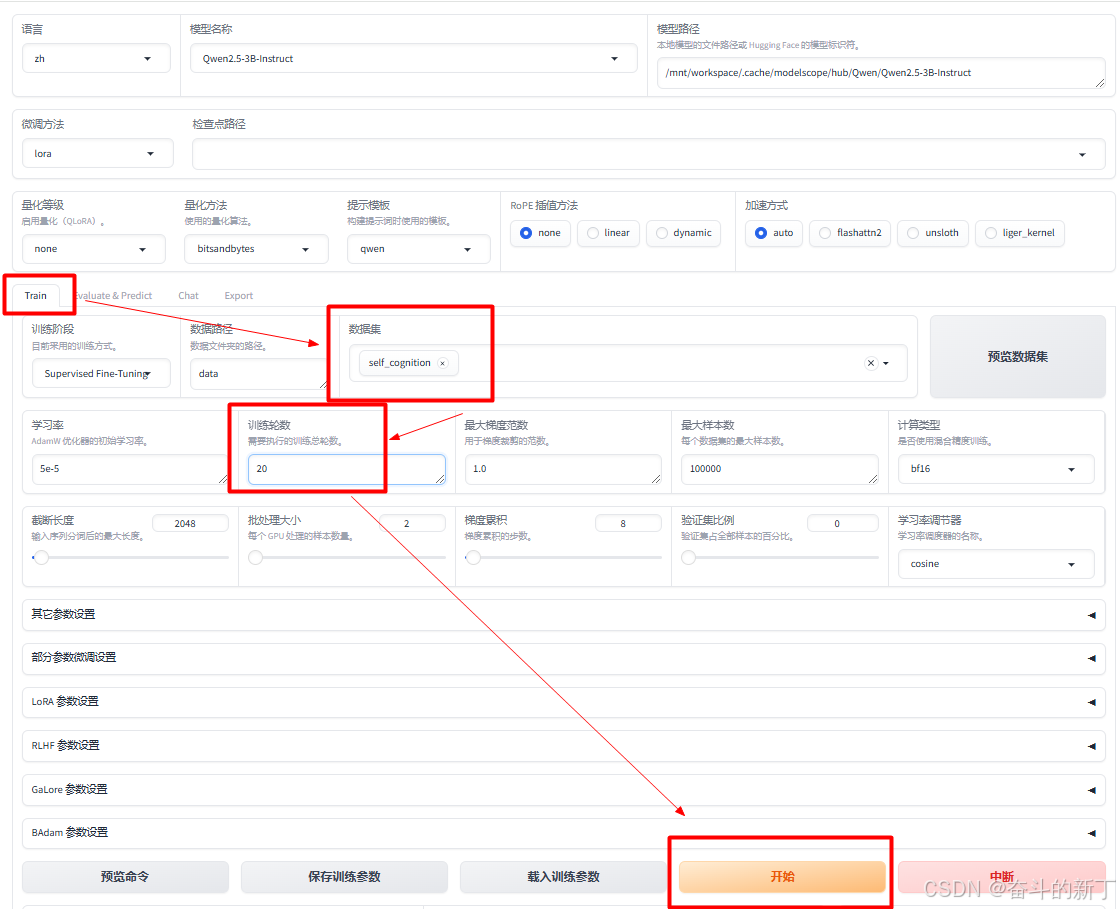
 训练完成后,我们再加载模型,选择我们刚才训练的结果,与其对话查看效果
训练完成后,我们再加载模型,选择我们刚才训练的结果,与其对话查看效果  到这里模型就训练完成了。
到这里模型就训练完成了。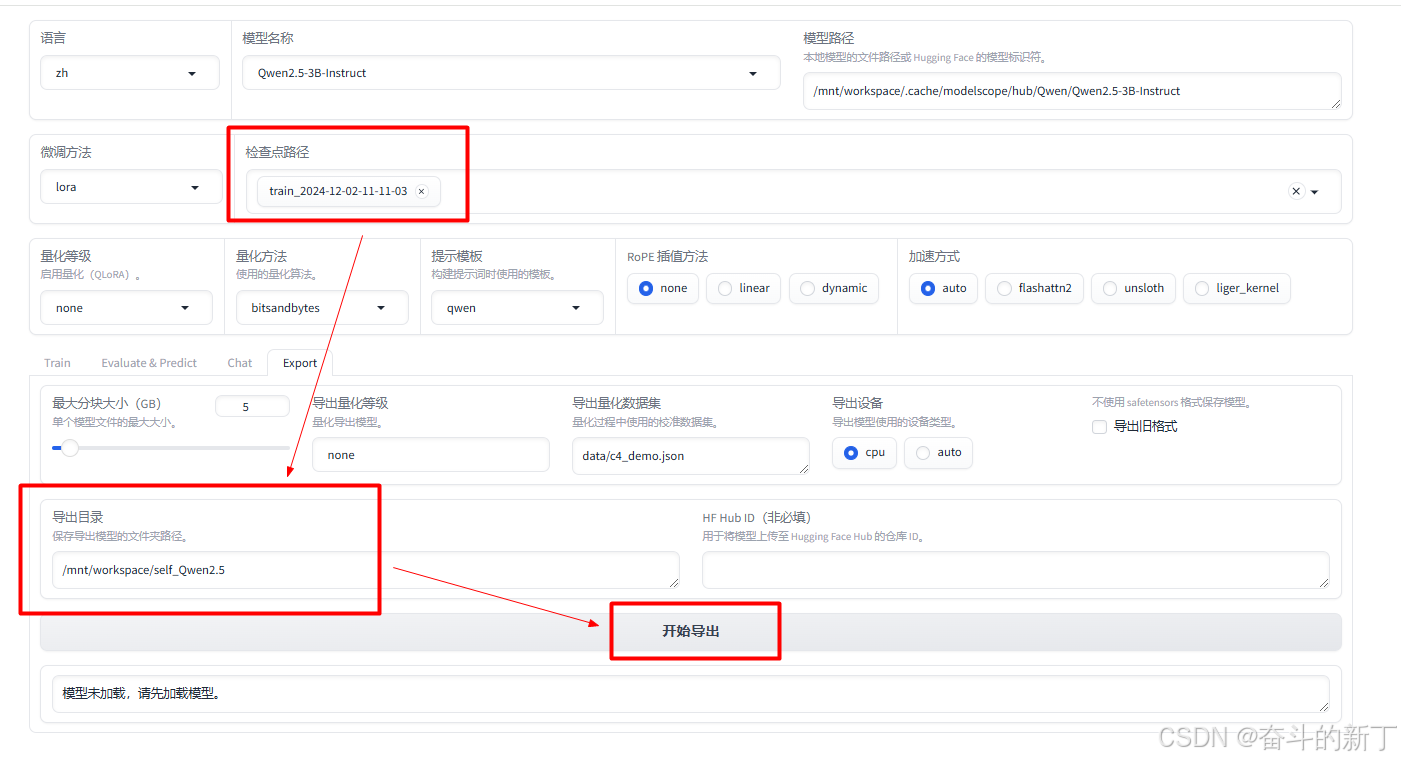 输入导出的目录地址,点击导出
输入导出的目录地址,点击导出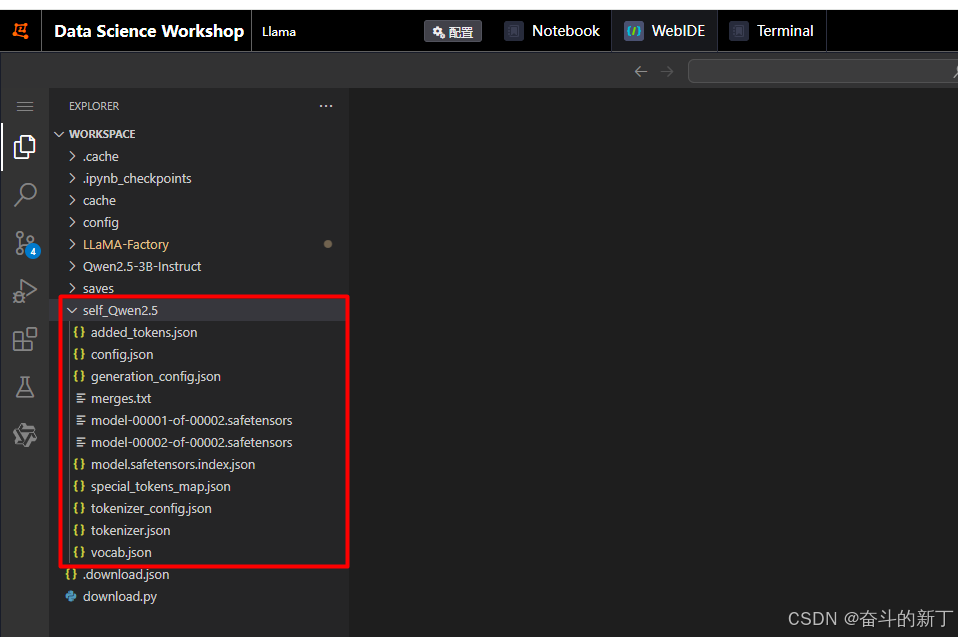
导出后就可以在ide中看到了。
模型微调参数分析(了解)
现对关键的几个参数进行分析(1)Finetuning method使用LoRA(Low-Rank Adaptation)作为微调类型。
其他参数​ 1.Full:这种方式就是从头到尾完全训练一个模型。想象一下,你有一块白纸,你要在上面画出一幅完整的画作,这就是Full Training。你从零开始,逐步训练模型,直到它能够完成你想要的任务。<br/> ​ 2.Freeze:这种方式有点像是在一幅半完成的画上继续作画。在模型中,有些部分(通常是模型的初级部分,如输入层或底层特征提取部分)是已经训练好的,这部分会被“冻结”,不再在训练过程中更新。你只更新模型的其他部分,这样可以节省训练时间和资源。 ​ 3.LoRA:这是一种比较新的技术,全称是“Low-Rank Adaptation”。可以理解为一种轻量级的模型调整方式。它主要是在模型的某些核心部分插入小的、低秩的矩阵,通过调整这些小矩阵来实现对整个模型的微调。这种方法不需要对原始模型的大部分参数进行重训练,从而可以在不牺牲太多性能的情况下,快速适应新的任务或数据。​ 4.QLoRA:这是在LoRA的基础上进一步发展的一种方法。它使用量化技术(也就是用更少的比特来表示每个数字),来进一步减少模型调整过程中需要的计算资源和存储空间。这样做可以使得模型更加高效,尤其是在资源有限的设备上运行时。(2)gradient_accumulation_steps
梯度累积步数,用于在更新模型前累积更多的梯度,有助于使用较小的批次大小训练大模型。选择多少步骤进行梯度累积取决于你的具体需求和硬件限制。一般来说,步数越多,模拟的批量大小就越大,但同时每次更新权重的间隔也更长,可能会影响训练速度和效率。
(3)lr_scheduler_type
学习率调度器类型
linear(线性):
描述:学习率从一个较高的初始值开始,然后随着时间线性地减少到一个较低的值。
使用场景:当你想要让模型在训练早期快速学习,然后逐渐减慢学习速度以稳定收敛时使用。
cosine(余弦):
描述:学习率按照余弦曲线的形状进行周期性调整,这种周期性的起伏有助于模型在不同的训练阶段探索参数空间。
使用场景:在需要模型在训练过程中不断找到新解的复杂任务中使用,比如大规模的图像或文本处理。
cosine_with_restarts(带重启的余弦):
描述:这是余弦调整的一种变体,每当学习率达到一个周期的最低点时,会突然重置到最高点,然后再次减少。
使用场景:适用于需要模型从局部最优解中跳出来,尝试寻找更好全局解的情况。
polynomial(多项式):
描述:学习率按照一个多项式函数减少,通常是一个幂次递减的形式。
使用场景:当你需要更精细控制学习率减少速度时使用,适用于任务比较复杂,需要精细调优的模型。
constant(常数):
描述:学习率保持不变。
使用场景:简单任务或者小数据集,模型容易训练到足够好的性能时使用。
constant_with_warmup(带预热的常数):
描述:开始时使用较低的学习率“预热”模型,然后切换到一个固定的较高学习率。
使用场景:在训练大型模型或复杂任务时,帮助模型稳定地开始学习,避免一开始就进行大的权重调整。
inverse_sqrt(逆平方根):
描述:学习率随训练步数的增加按逆平方根递减。
使用场景:常用于自然语言处理中,特别是在训练Transformer模型时,帮助模型在训练后期进行细微的调整。
reduce_lr_on_plateau(在平台期降低学习率):
描述:当模型的验证性能不再提升时,自动减少学习率。
使用场景:适用于几乎所有类型的任务,特别是当模型很难进一步提高性能时,可以帮助模型继续优化和提升。1234567891011121314151617181920212223242526272829303132
(4)warmup_steps  学习率预热步数。
学习率预热步数。
预热步数(Warmup Steps):
这是模型训练初期用于逐渐增加学习率的步骤数。在这个阶段,学习率从一个很小的值(或者接近于零)开始,逐渐增加到设定的初始学习率。这个过程可以帮助模型在训练初期避免因为学习率过高而导致的不稳定,比如参数更新过大,从而有助于模型更平滑地适应训练数据。
例如,如果设置warmup_steps为20,那么在前20步训练中,学习率会从低到高逐步增加。
预热步数的具体数值通常取决于几个因素:
训练数据的大小:数据集越大,可能需要更多的预热步骤来帮助模型逐步适应。模型的复杂性:更复杂的模型可能需要更长时间的预热,以避免一开始就对复杂的参数空间进行过激的调整。总训练步数:如果训练步数本身就很少,可能不需要很多的预热步骤;反之,如果训练步数很多,增加预热步骤可以帮助模型更好地启动。
(5)save_steps eval_steps
保存和评估的步数
(6)learning_rate
 学习率是机器学习和深度学习中控制模型学习速度的一个参数。你可以把它想象成你调节自行车踏板力度的旋钮:旋钮转得越多,踏板动得越快,自行车就跑得越快;但如果转得太快,可能会导致自行车失控。同理,学习率太高,模型学习过快,可能会导致学习过程不稳定;学习率太低,模型学习缓慢,训练时间长,效率低。
学习率是机器学习和深度学习中控制模型学习速度的一个参数。你可以把它想象成你调节自行车踏板力度的旋钮:旋钮转得越多,踏板动得越快,自行车就跑得越快;但如果转得太快,可能会导致自行车失控。同理,学习率太高,模型学习过快,可能会导致学习过程不稳定;学习率太低,模型学习缓慢,训练时间长,效率低。
常见的学习率参数包括但不限于:
1e-1(0.1):相对较大的学习率,用于初期快速探索。
1e-2(0.01):中等大小的学习率,常用于许多标准模型的初始学习率。
1e-3(0.001):较小的学习率,适用于接近优化目标时的细致调整。
1e-4(0.0001):更小的学习率,用于当模型接近收敛时的微调。
5e-5(0.00005):非常小的学习率,常见于预训练模型的微调阶段,例如在自然语言处理中微调BERT模型。
选择学习率的情况:
快速探索:在模型训练初期或者当你不确定最佳参数时,可以使用较大的学习率(例如0.1或0.01),快速找到一个合理的解。
细致调整:当你发现模型的性能开始稳定,但还需要进一步优化时,可以减小学习率(例如0.001或0.0001),帮助模型更精确地找到最优解。
微调预训练模型:当使用已经预训练好的模型(如在特定任务上微调BERT)时,通常使用非常小的学习率(例如5e-5或更小),这是因为预训练模型已经非常接近优化目标,我们只需要做一些轻微的调整。12345678910
(7)精度相关
FP16 (Half Precision,半精度):
这种方式使用16位的浮点数来保存和计算数据。想象一下,如果你有一个非常精细的秤,但现在只用这个秤的一半精度来称重,这就是FP16。它不如32位精度精确,但计算速度更快,占用的内存也更少。
BF16 (BFloat16):
BF16也是16位的,但它在表示数的方式上和FP16不同,特别是它用更多的位来表示数的大小(指数部分),这让它在处理大范围数值时更加稳定。你可以把它想象成一个专为机器学习优化的“半精度”秤,尤其是在使用特殊的硬件加速器时。
FP32 (Single Precision,单精度):
这是使用32位浮点数进行计算的方式,可以想象为一个标准的、全功能的精细秤。它在深度学习中非常常见,因为它提供了足够的精确度,适合大多数任务。
Pure BF16:
在表示数的方式上和FP16不同,特别是它用更多的位来表示数的大小(指数部分),这让它在处理大范围数值时更加稳定。你可以把它想象成一个专为机器学习优化的“半精度”秤,尤其是在使用特殊的硬件加速器时。
FP32 (Single Precision,单精度):
这是使用32位浮点数进行计算的方式,可以想象为一个标准的、全功能的精细秤。它在深度学习中非常常见,因为它提供了足够的精确度,适合大多数任务。
Pure BF16:
这种模式下,所有计算都仅使用BF16格式。这意味着整个模型训练过程中,从输入到输出,都在使用为机器学习优化的半精度计算。123456789101112
(8)LoRA的秩 LoRA(Low-Rank Approximation)是一种用于大模型微调的方法,它通过降低模型参数矩阵的秩来减少模型的计算和存储成本。在微调大模型时,往往需要大量的计算资源和存储空间,而LoRA可以通过降低模型参数矩阵的秩来大幅度减少这些需求。
LoRA(Low-Rank Approximation)是一种用于大模型微调的方法,它通过降低模型参数矩阵的秩来减少模型的计算和存储成本。在微调大模型时,往往需要大量的计算资源和存储空间,而LoRA可以通过降低模型参数矩阵的秩来大幅度减少这些需求。
具体来说,LoRA使用矩阵分解方法,将模型参数矩阵分解为两个较低秩的矩阵的乘积。这样做的好处是可以用较低秩的矩阵近似代替原始的参数矩阵,从而降低了模型的复杂度和存储需求。
在微调过程中,LoRA首先将模型参数矩阵分解为两个较低秩的矩阵。然后,通过对分解后的矩阵进行微调,可以得到一个近似的模型参数矩阵。这个近似矩阵可以在保持较高性能的同时大幅度减少计算和存储资源的使用。
LoRA的秩可以根据模型的需求进行设置。一般来说,秩越低,模型的复杂度越低,但性能可能会受到一定的影响。所以在微调大模型时,需要根据具体情况来选择合适的秩大小,以平衡模型的性能和资源的使用。
建议根据硬件条件进行选择,一般可选16或32,模型微调效果较佳。
(9)LoRA的缩放系数
缩放系数是用来表示模型中每个层的相对重要性的参数。在LoRA中,每个层都有一个缩放系数,用于调整该层对总体损失函数的贡献。较高的缩放系数表示该层的权重更大,较低的缩放系数表示该层的权重较小。
缩放系数的选取可以根据问题的特点和需求进行调整。通常情况下,较低层的缩放系数可以设置为较小的值,以保留更多的原始特征信息;而较高层的缩放系数可以设置为较大的值,以强调更高级别的抽象特征。
本地部署
下载模型
首先把导出的模型下载到本地电脑,但是这种格式ollama无法识别,我们需要转成gguf格式。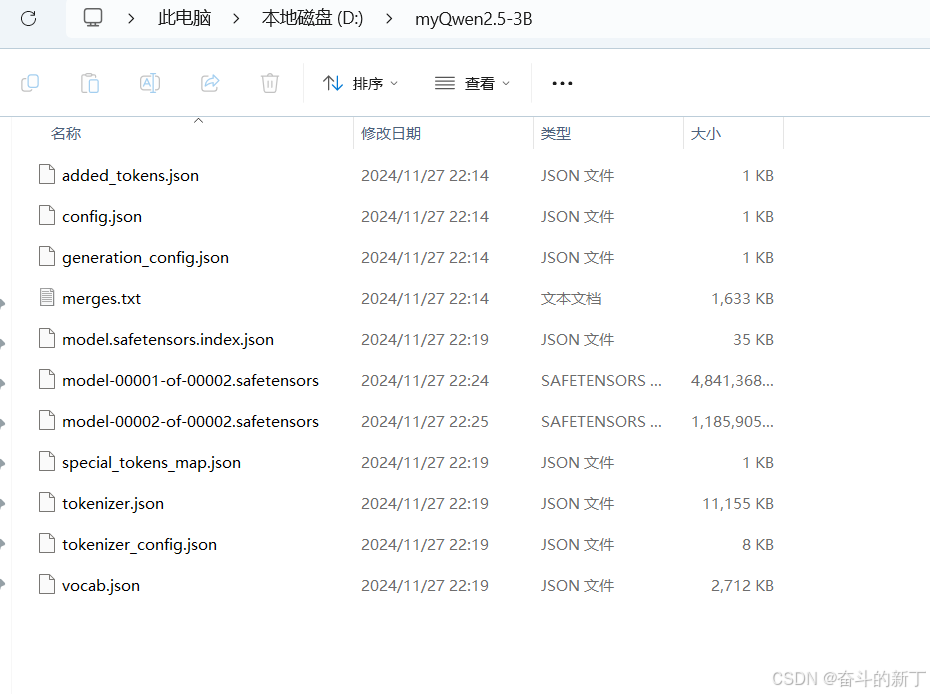
安装Cmake
下载地址 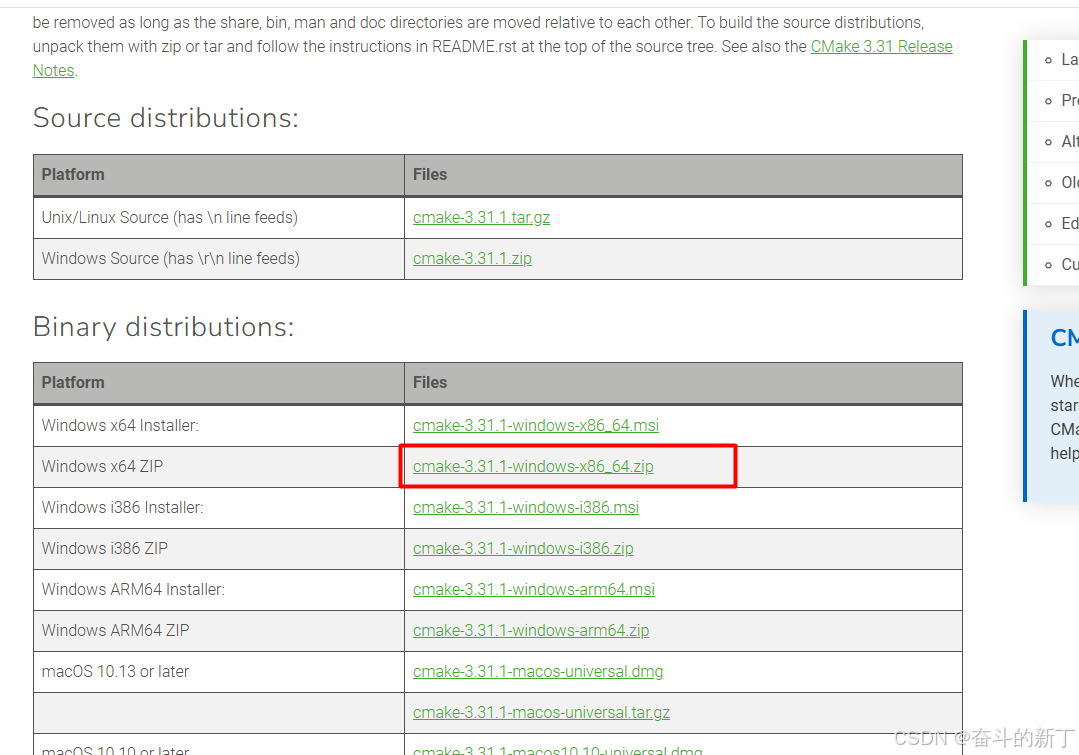 解压,设置Path环境变量D:\CMake\bin
解压,设置Path环境变量D:\CMake\bin
cmd查看 cmake -version 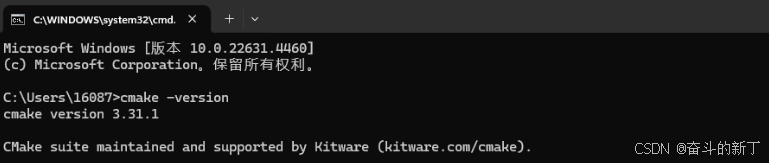
安装MinGW/Visual Studio
还需要安装编译器,可以安装MinGW:参考教程<br/> 或者省事点就安装Visual Studio,勾选C++编译环境<br/> 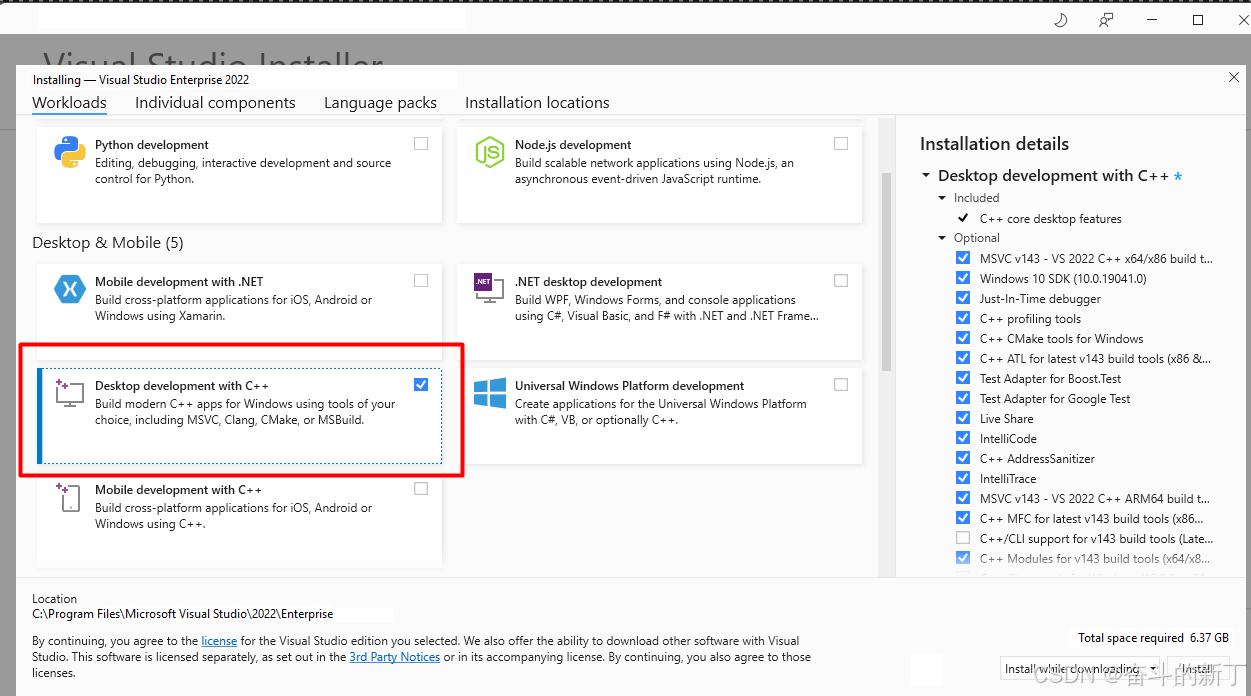
安装llama.cpp
git clone https://github.com/ggerganov/llama.cpp.git1
拉取到本地,在llama.cpp文件加下cmd然后执行命令编译
mkdir build
cd build
cmake ..
cmake --build . --config Release1234
下载llama.cpp执行所需的依赖
pip install -r requirements.txt1
转换格式
做完一切后,我们继续执行
python convert_hf_to_gguf.py D:\myQwen2.5-3B1
此时模型文件夹D:\myQwen2.5-3B下会生成一个myQwen2.5-3B-F16.gguf文件<br/> 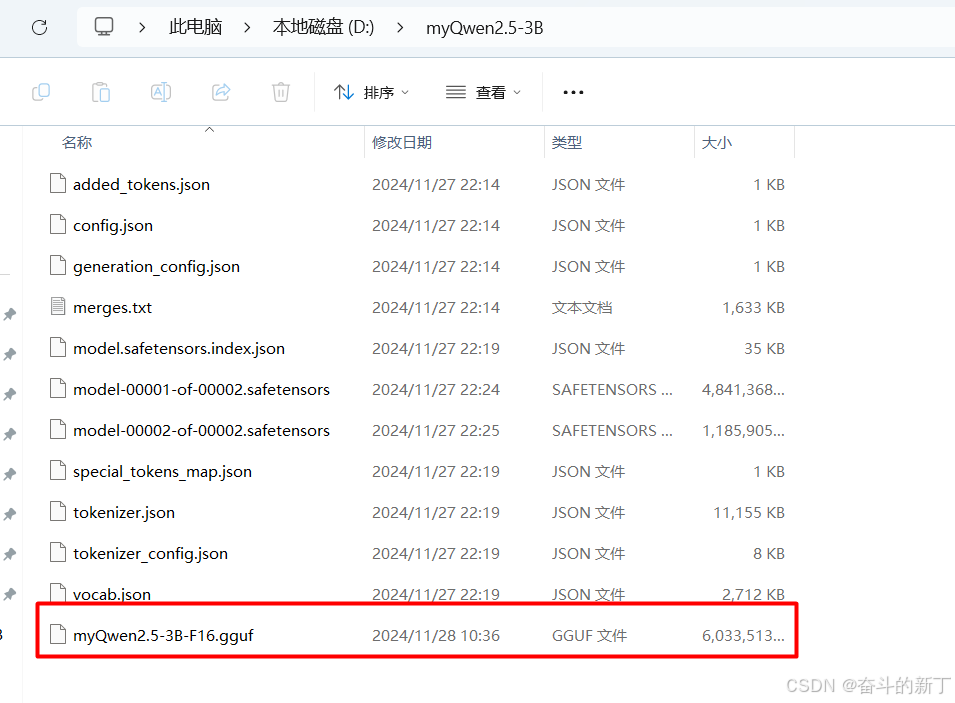
量化(可以跳过)
转换完格式后其实就可以直接加载到ollama中使用了,但是myQwen2.5-3B-F16.gguf这个文件有6个多G,我们可以通过量化减少体积。<br/> 量化所需要的工具在llama.cpp的发布版中
下载地址<br/> 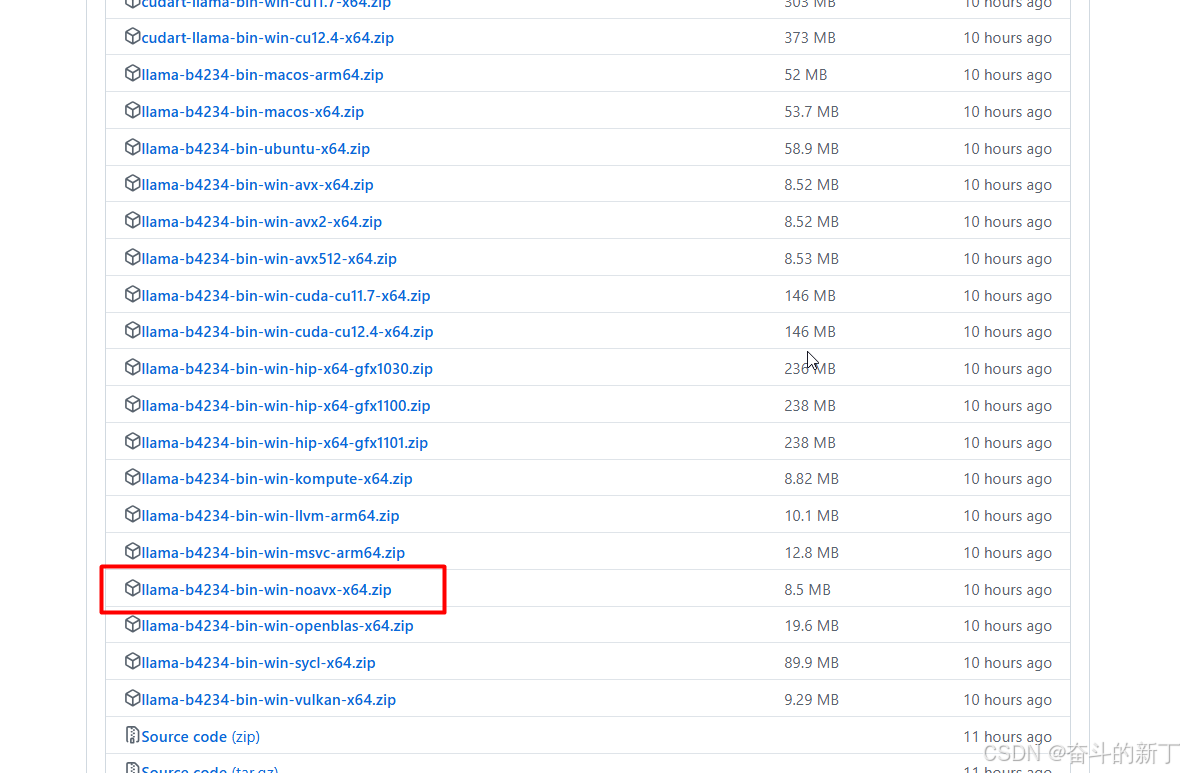 下载这个,解压。<br/> 在解压的文件夹中执行命令,使用Q4_K_M量化算法
下载这个,解压。<br/> 在解压的文件夹中执行命令,使用Q4_K_M量化算法
.\llama-quantize.exe D:\myQwen2.5-3B\myQwen2.5-3B-F16.gguf D:\myQwen2.5-3B\myQwen2.5-3B-Q4_K_M.gguf Q4_K_M1
执行完成后D:\myQwen2.5-3B下会生成myQwen2.5-3B-Q4_K_M.gguf<br/> 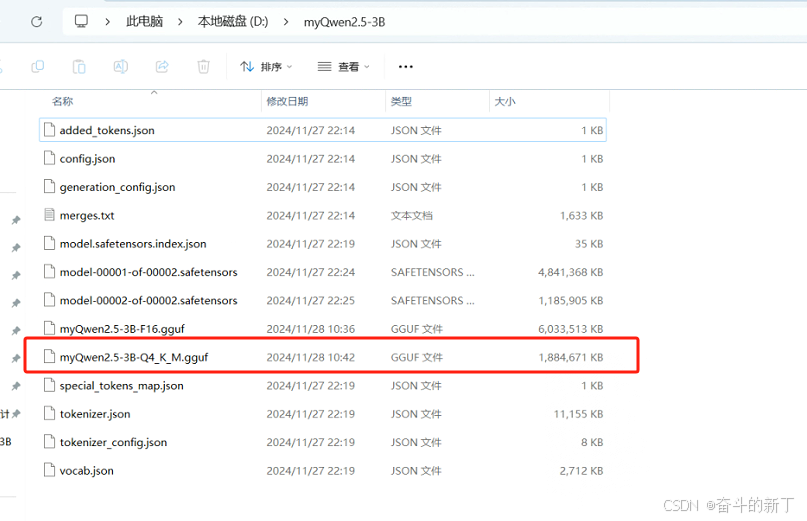 <br/> 这里可以看到体积变成了1G多。
<br/> 这里可以看到体积变成了1G多。
运行模型
在模型文件夹D:\myQwen2.5-3B下,新建文件Modelfile<br/> 输入
FROM ./myQwen2.5-3B-Q4_K_M.gguf
TEMPLATE """{{ if .System }}<|start_header_id|>system<|end_header_id|>{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>"""
SYSTEM """You are a helpful assistant. 你是一个乐于助人的助手。"""
PARAMETER temperature 0.2
PARAMETER num_keep 24
PARAMETER stop <|start_header_id|>
PARAMETER stop <|end_header_id|>
PARAMETER stop <|eot_id|>1234567891011121314
在cmd中执行
ollama create myQwen2.5-3B -f Modelfile
ollama run myQwen2.5-3B12
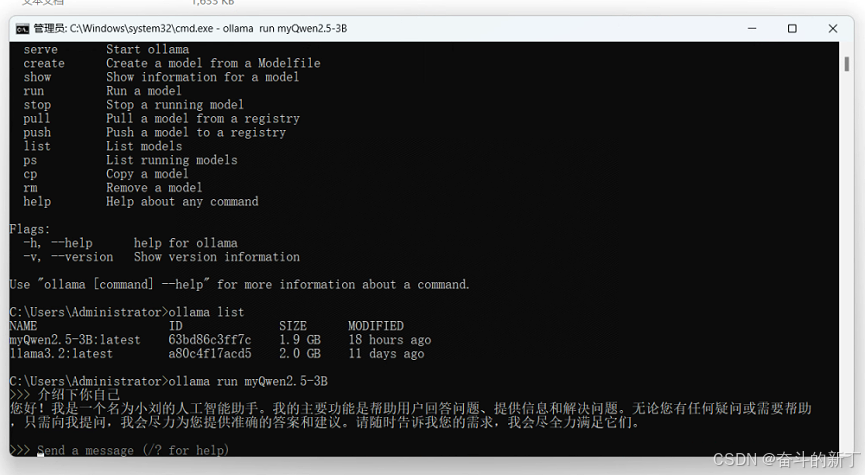 <最后就可以在ollama中与咱们训练的大模型进行对话啦。后续可以使用dify等工具生成可视化web对话页面。
<最后就可以在ollama中与咱们训练的大模型进行对话啦。后续可以使用dify等工具生成可视化web对话页面。
————————————————
<br/>
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/qq_42374233/article/details/144180042
文章由大象博客原创,转载引用需注明出处:大象博客(https://daxiang.tech)
暂无评论数据